3.4 KiB
3.4 KiB
理论基础
二叉树的种类
满二叉树:如果一棵二叉树只有度为 0 的结点和度为 2 的结点,并且度为 0 的结点在同一层上,则这棵二叉树为满二叉树。
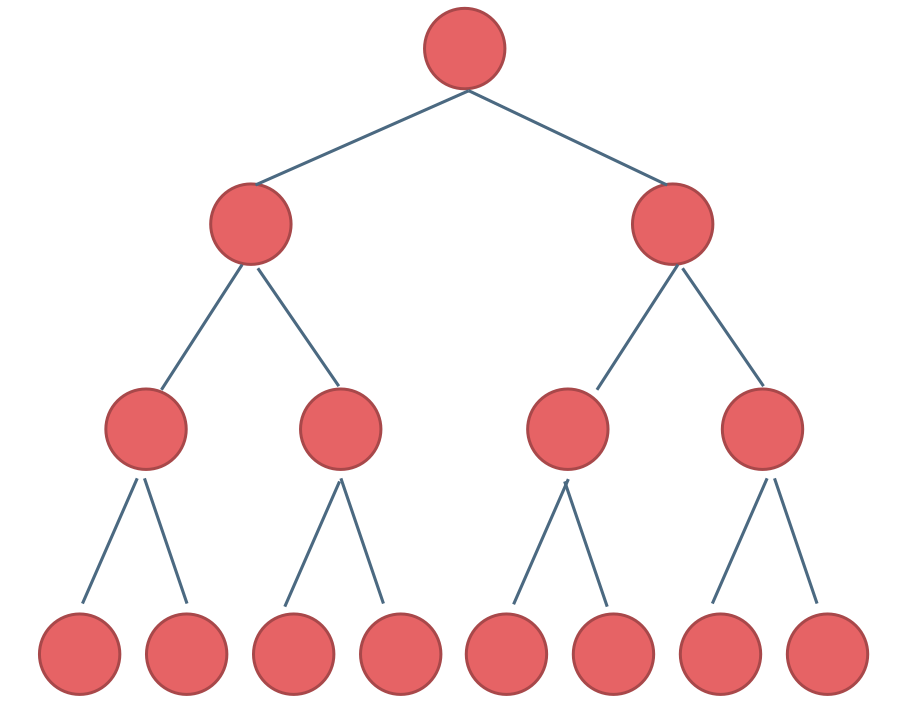
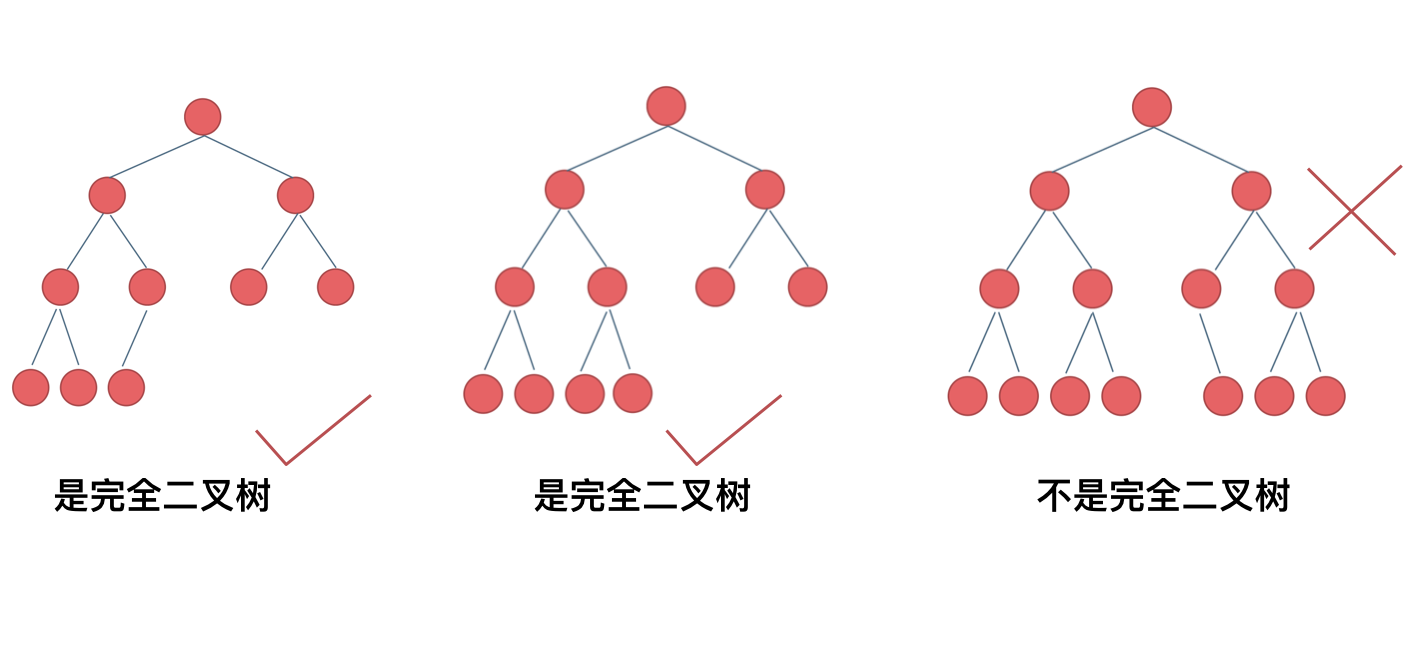
完全二叉树:除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。
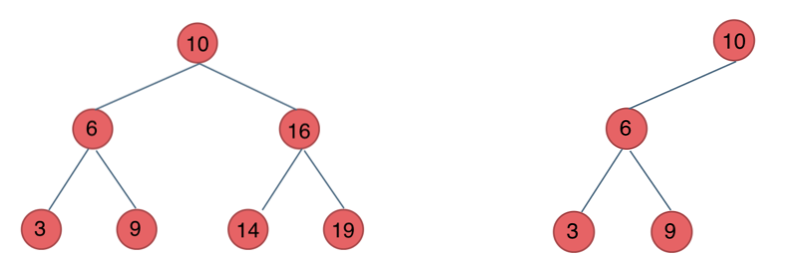
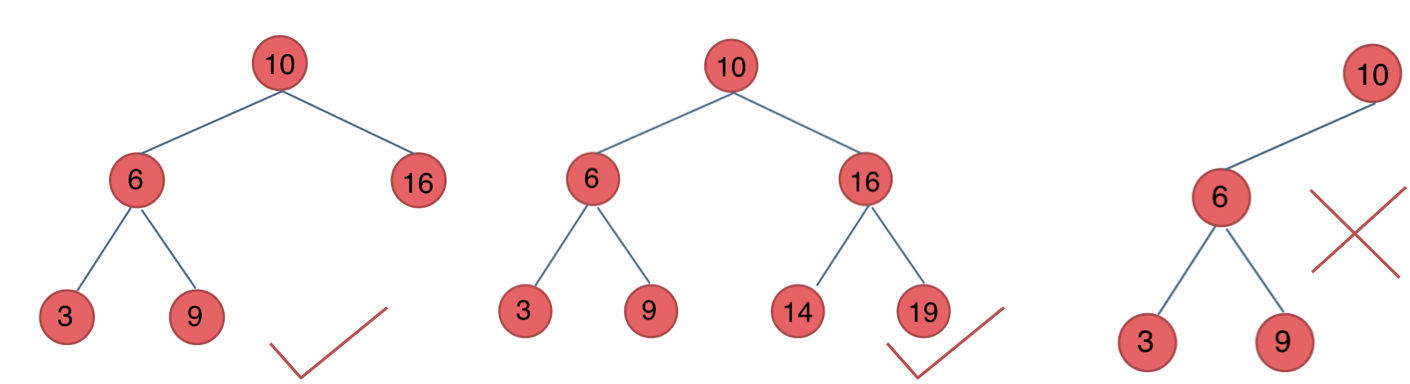
二叉搜索树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉排序树。
平衡二叉搜索树:又被称为 AVL(Adelson-Velsky and Landis)树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过 1,并且左右两个子树都是一棵平衡二叉树。
二叉树的存储方式
- 链式,用链表来存储
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};
- 数组存储
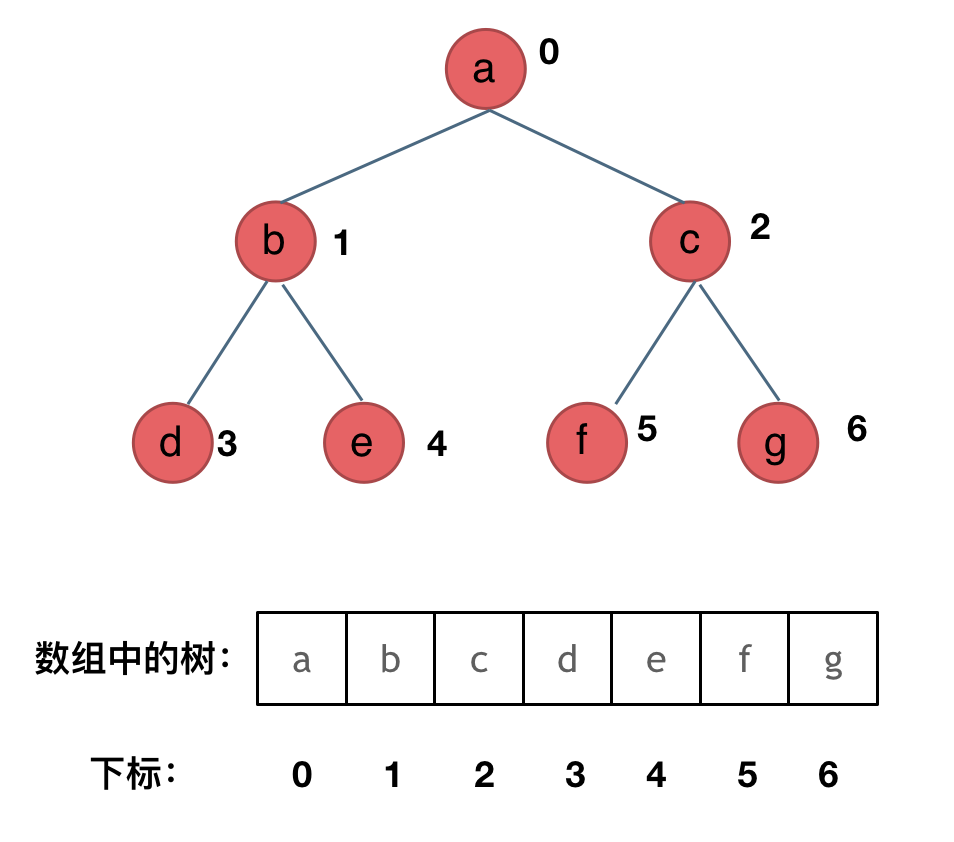
如果父节点的数组下标是 i,那么它的左孩子就是 i * 2 + 1,右孩子就是 i * 2 + 2。
遍历方式
- 深度优先遍历
- 前序遍历(递归法,迭代法)
- 中序遍历(递归法,迭代法)
- 后序遍历(递归法,迭代法)
- 广度优先遍历
- 层序遍历(迭代法)
深度优先遍历:
- 不保留全部节点状态,占用空间小
- 有回溯操作(即有入栈、出栈操作),运行速度慢
- 深度很大的情况下效率不高
广度优先遍历:
- 保留全部节点状态,占用空间大
- 无回溯操作(即无入栈、出栈操作),运行速度快
- 对于解决最短或最少问题特别有效,而且寻找深度小(每个结点只访问一遍,结点总是以最短路径被访问,所以第二次路径确定不会比第一次短)
区分前中后序遍历的方法:
- 前序遍历:中左右
- 中序遍历:左中右
- 后序遍历:左右中
技巧
- 深度优先搜索从下往上,广度优先搜索从上往下,所以如果需要处理从上往下并且状态积累的情形 (e.g. s0404 && s0257) 可以先创建一个结构体用来描述节点状态,然后用 BFS 遍历。
- 写递归时,如果
TreeNode *ptr不足以描述当前节点状态,则可以写一个辅助函数,接收TreeNode *ptr为参数,返回TreeNodeState来描述当前节点的状态。参考 s0098 - 另一种需要结构体的地方是需要获得每个节点路径(即根节点到当前节点所经过的路径),可以用 DFS 或 BFS 遍历。
- 如果要处理不是从上往下积累状态,而是按照一定规则遍历节点并积累状态的情况(e.g. s0538)则考虑用三种递归遍历方式中的一种来遍历,并用一个全局变量来记录遍历状态。另外,务必理解并记忆每种遍历方式的动态图!